������Ѷ��κ����/�ģ����գ�MLCommons������MLPerf Training v1.0��һ�ֱ�������������ʾӢΰ��ϻ������ṩ�ĸ��ִ���NVIDIA������ϵͳ�ٴ�ȡ���˳�ɫ�ijɼ���������AI���������Ľ�һ��������ҲΪ���ظ��������Ӧ���ṩ���������������������������ڡ�
ȫ�����AIģ��ѵ���ٶ�
MLPerf ����ѧ���硢�о�ʵ���Һ�ҵ����ʿ��ɵ��˹��ǻ��������ˣ����ڡ����칫ƽ��ʵ�û�����ʹ����ΪӲ�塢����ͷ����ѵ�����ƶ�Ч���ṩ������������ȫ����Ԥ��������ִ�С��û����Ի��ڵ�����õ�AI�������غͳ��������Ǽ�����Ӿ�����Ȼ���Դ������Ƽ�ϵͳ��ǿ��ѧϰ�ȡ�
��ǰ��Ӣΰ����̬ϵͳһֱ�ڲ����б��ֳ����ijɼ���������2020��7�µ����ĵ�����MLPerf����Ӣΰ��A100 Tensor Core GPU ��ȫ�������������չ����������ܡ���ʵ���������Ĵ��ģ����������棬����HDR InfiniBandʵ�ֶ��DGX A100ϵͳ�����ķ�������ȺDGX SuperPODϵͳҲͬ��������ҵ���������ܡ�
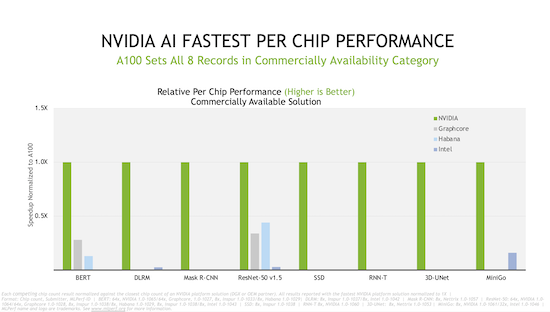
����MLCommons����һ�����£���Ӣΰ����̬ϵͳ���Ĵβμ�MLPerfѵ�����ԡ���оƬ�Ա��У�Ӣΰ�P�����������������ý���������Ե����а���������ж������˼�¼��
�����У��ҹ�˾������ʮ��������ϵͳ�����˲��ԣ���Ӣΰ��AI������ϵͳ������75%����Ӣΰ���⣬�������˴�������ʿͨ�����Ρ��˳������롢���������ȡ�����Google��Graphcore��Habana��Ӣ�ض������̿Ƽ�ʹ������ϵͳ������Ӣΰ�P�������������NVIDIA A100 GPU����ƻ�Ϊ����ʵ������������PCIe������NVIDIA A100 GPU���Լ�������40��NVIDIA��֤ϵͳ��
ʵ����һ�ɼ������ԭ�����ڣ�����A100 Tensor Core GPU��ȥ���Ѿ��۰�MLPerf���ԣ�Ӣΰ�﹤��ʦ��ʹ����GPU��ϵͳ�������AI�����������ʵ���˽��������磬ͨ��ȫ�µ�ʹ��CUDA Graphs��������������ģ�͵ķ������ܹ������ȥ�����е�CPUƿ�������ڴ��ģ������ʹ�õ���NVIDIA SHARP���������罻�����ڵĶ���ͨ�Ź������Ӷ��������������͵ȴ�CPU��ʱ�䡣
������������������
�����һ�ֲ��Գɼ���Ӣΰ�ォ��������������2.1������ͨ����β��Խ���ۺ�������Ӣΰ����������ʱ���ڽ���������˶��6.5�������ܵĿ���������ҲΪ�ͻ�����չ�˹����ܵ�ȫ����������ṩ�˸�����ܡ�
��ǰ����AIӦ�ð����У���������ѧϰ��ͼ�����ʶ������������ʶ������߶ȱ�ʶ����Ȼ���Դ������Ѿ����㷺Ӧ�ã��������е�MiniGo��Mask R-CNN��SSD��Ҳ��Ӧ��������Ӧ�����������MLPerf�����м����RNN-T��3D-UNet���ԣ�ҲԤʾ����ҵ������������ʶ������ҽѧͼ�����ȫ������Ӣΰ�P�ϻ����ڰ�������еĴ���¼���֣�Ҳ��ζ����ʵ�ʵ��˹�����Ӧ���У��ܹ��������ߵ�Ч�ʡ�
Ŀǰ���¹���֢�о����ľ���Ӣΰ��չ����������3D-UNet�ȴ��¼�������ҽ���г�����ʵ������ҽѧͼ���ϵĹ��ܡ���һ����Ҳ֤����MLPerf�IJ��Խ���ܹ���IT�����Ϳ������Լ���IJο������ҵ����ʵĽ���������Լ����ض���Ŀ��Ӧ�á����β����У�Ӣΰ��AI��3D-UNet�ϵ����ܱ��������ǵڶ�����6��֮�ࡣ

 �߲�
�߲� ��̸
��̸

 �۵�
�۵�
