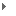摘 要:用友UAP的数据平台具备了大数据处理与分析的能力,它主要依靠非结构化数据处理平台UDH(UAP Distribute for Hadoop)来完成。UDH包括分布式文件系统、列存数据库,涵盖分布式批处理、实时分析查询、流处理和基于内存的分布式批处理的分布式分析计算框架类,以及分布式数据挖掘。
在大数据备受关注的今天,企业不能盲从,而是应该明白大数据为什么会如此之热,为什么去关注它。其中一个重要原因就是,大数据不同于普通数据,它增加了很多半结构化数据和非结构化数据,并且其数量级和价值不可同日而语。
IDC的报告显示,目前大数据的1.8万亿GB容量中,非结构化数据占到了80%~90%之间,并且到2020年将以44倍的发展速度增长。如果说结构化数据用详实的方式记录了企业的生产交易活动,那么非结构化数据则是掌握企业命脉的关键内容,所反映的信息蕴含着诸多企业效益提高的机会。因此,只有解决非结构化数据的分析困难,才能有效挖掘这些数据背后的价值,驱动企业价值提升。
提到大数据相关的技术,很多内行人士一定会联想到Hadoop。因为Hadoop是一种分布式数据和计算的框架,它很擅长存储大量的半结构化的数据集。适用于大规模集群上的海量数据处理,使得程序员可以轻松地编写分布式并行程序,并将其运行于计算机集群上,完成大规模数据的计算。
用友基于Hadoop开源产品体系发布UDH产品,并围绕UDH开发了一系列解决企业大数据应用需求的管理工具和集成、开发、展现组件。使企业可实现大规模结构化、非结构化数据的集中、一体化的分析处理需求。

专门为大型企业与组织提供计算平台的用友UAP,包含了开发平台、集成平台、动态建模平台、商业分析平台、数据平台、轻量平台、云管理平台、移动应用平台、WEB平台、RIA平台、社交平台等多个领域产品。其中数据平台具备了大数据处理与分析的能力,它主要依靠非结构化数据处理平台UDH(UAP Distribute for Hadoop)来完成。UDH包括分布式文件系统、列存数据库,涵盖分布式批处理、实时分析查询、流处理和基于内存的分布式批处理的分布式分析计算框架类,以及分布式数据挖掘。
UDH产品架构
用友UAP数据平台中的UDH是从一个整合性解决方案角度,帮企业去节省大部分的集群管理、服务监控、部署方面的成本。使用UDH,会把整个系统的人力投入降到1到2个工程师就可以去运维一个相当大规模的一个集群。通常即便企业由较大的技术团队和较强的技术力量储备,也需要数月甚至一年以上时间,使用UDH,可以把时间缩短到一个月左右。这对企业来讲是非常重要的,因为它意味着更小的成本、更快的投资回报。
UDH平台基于开源hadoop,hive,storm、Spark等进行了优化,涵盖大规模非结构化数据集成、存储和分析计算。集成YARN,支持多种分布式计算框架(MapReduce, Spark、Storm等),同时提供更高效的存储结构。单集群可达100台以上,可管理PB级数据。
用友UAP的UDH在非结构化数据的实时计算和分析上具有独特的技术优势。
第一,多集群实时计算。UDH可达到秒级延迟,异常情况在几秒内就能检测到。 可处理的数据量大,总流量至少达到100Gb/s。UDH可提供5个集群,900个节点,每个节点2-4个slot。可以合理利用云存储的空闲资源。UDH可实时进行日志统计、网页分析、图片处理、人脸识别等。每天处理约数据量120TB,200亿条;