本文结合电信运营商的需求,对DPI数据进行实时的采集及处理,提出一种基于流式计算的DPI数据处理方案,能够将获得DPI数据实时信息的时延降低到分钟级,甚至秒级,实现对电信用户上网信息的实时处理、监测及分类汇总,为之后进行的大数据应用提供了良好基础。
2 流式处理概述
传统基于MapReduce大数据处理技术实际上是一种批处理方式,如图1所示。批处理模式首先要完成数据的累积和存储,然后Hadoop客户端将数据上传到HDFS上,最后才启动Map/Reduce进行数据处理,处理后再写入到HDFS。这种方式必须要所有数据都要准备好,然后统一进行集中计算和价值发现,无法满足实时性的要求。

图1 批处理流程
图1 基于MapReduce的大数据处理
2015年,Nathan Marz提出了实时大数据处理框架Lambda架构[5],整合了离线计算和实时计算,能够满足实时系统高容错、低时延和可扩展等要求,并且可集成Hadoop、Kafka、Storm、Spark及HBase等各类大数据组件。
一个典型的Lambda架构如图2所示,主要使用的场景是逻辑复杂且延迟低的程序。数据会分别灌入实时系统和批处理系统,然后各自输出自己的结果,结果会在查询端进行合并。
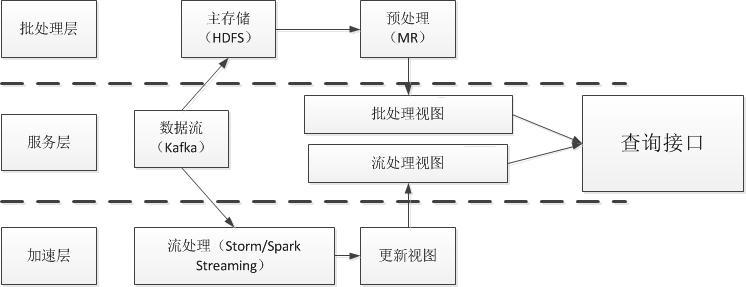
图2 Lambda架构图
3 流式计算架构对比
流式计算对系统的容错、时延、可扩展及可靠性能力提出了很高的要求,当前有许多流式计算框架(如Spark streaming[10]、Storm[11]、Kafka Stream[12]、Flink[13]和PipelineDB[14]等)已经广泛应用于各行各业,并且还在不断迭代发展,适用的场景也各不相同。
3.1 Spark streaming
Spark是由加州大学伯克利分校AMP实验室专门为大数据处理而设计的计算框架[6]。Spark Streaming是建立在Spark上的实时计算框架,是Spark的核心组件之一,通过它内置的API和基于内存的高效引擎,用户可以结合流处理、批处理和交互式查询开发应用。
Spark Streaming并不像其他流式处理框架每次只处理一条记录,而是将流数据离散化处理,每次处理一批数据(DStream),使之能够进行秒级以下的快速批处理,执行流程如图3所示。Spark Streaming的Receiver并行接收数据,将数据缓存至内存中,经过延迟优化后Spark引擎对短任务(几十毫秒)进行批处理。这样设计的好处让Spark Streaming能够同时处理离线处理和流处理问题。
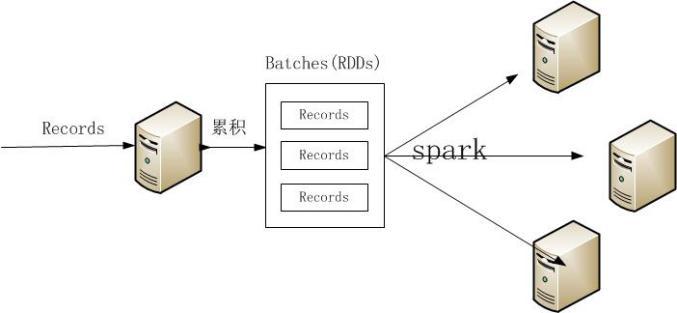
图3 Spark Streaming执行流程
Spark Streaming能在故障报错下迅速恢复状态,整合了批处理与流处理,内置丰富高级算法处理库,发展迅速,社区活跃。毫无疑问,Spark Streaming是流式处理框架的佼佼者。缺点是由于需要累积一批小文件才处理,因此时延会稍大,是准实时系统。
 高层
高层 访谈
访谈

 观点
观点
