
Storm的特点是成熟,是流式处理框架实际上的标准,模型、编程难度都比较复杂,框架采用循环处理数据,对系统资源,尤其是CPU资源消耗很大,当任务空闲时,需要sleep程序,减少对资源的消耗。Spark Streaming兼顾了批处理以及流式处理,并且有Spark的强大支持,发展潜力大,但与Kafka的接口平滑性不够。Kafka Stream是Kafka的一个开发库,具有入门、编程、部署运维简单的特点,并且不需要部署额外的组件,但对于多维度的统计来说,需要基于不同topic来做分区,编程模型复杂。Flink跟Spark Streaming很像,不同的是Flink把所有任务当成流来处理,在迭代计算、内存管理方面比Spark Streaming稍强,缺点是社区活跃度不高,还不够成熟;PipelineDB是一个流式计算数据库,能执行简单的流式计算任务,优势是基本不需要开发,只要熟悉SQL操作均可以轻松使用,但对于集群计算,需要商业上的支持。
4 DPI数据处理方案
基于实际任务需求以及上文流式框架的对比,由于Kafka Stream编程难度小,不需要另外安装软件,与Kafka等组件无缝连接,比较稳定,并且各种性能均比较优秀,因此本文选择了Kafka Stream作为流式处理的核心组件。
4.1宽带DPI处理
为了完成宽带DPI数据的实时抓包、资料填补、清洗、转换及并入库等工作,应用了上述DPI数据处理方案。具体项目方案如图5所示:
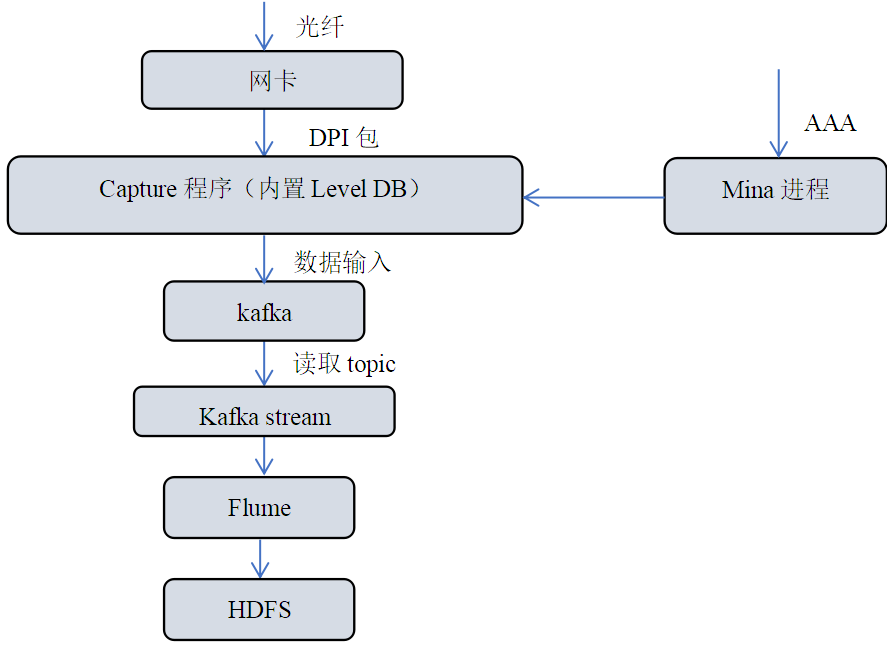
图5 广州宽带DPI处理方案
Mina进程是一个JAVA程序,基于mina框架开发,主要接收AAA数据包,获得用户账户信息,解析计算,并持久化到redis,最后发送给抓包(Capture)程序。Capture程序由C语言编写,使用开源pcap抓取网卡http包,解析,结合用户帐号资料,把DPI写入到Kafka中。Kafka stream完成DPI的实时清洗和转换工作。
Flume[15]是Cloudera开源的分布式可靠、可用、高效的收集,聚合和移动不同数据源的海量数据系统,配置简单,基本无需开发,资源消耗低,支持传输数据到HDFS,非常适合与大数据系统结合。本项目将流式处理完后的数据通过Flume从Kafka中写入到HDFS,建立hive表,为上层应用提供数据。
Kafka Stream采用自主研发的ETL框架[16],负责数据过滤(图片、视频等去掉),数据处理(获取网络ID、字段解析等)。ETL框架采用JAVA语言开发,支持多种数据源,包括普通文本、压缩格式及xml立体格式等。支持多种大数据计算框架,包括Map/Reduce、Spark streaming、Kafka Stream和Flume等;具有扩展方便、字段校验、支持字段的通配符及支持维表查询等功能。在运维方面,支持变量引用以及出错处理等功能。
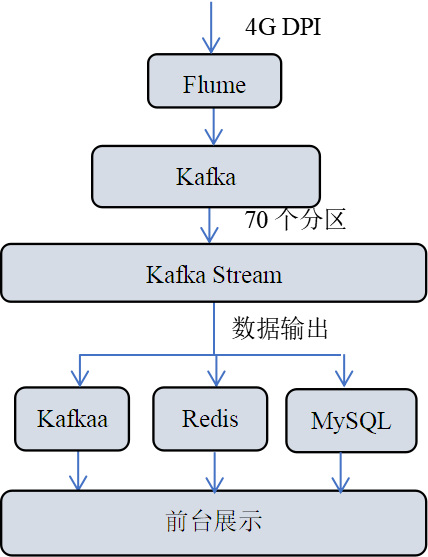
4.24GDPI实时统计
以电信4G DPI信息作为数据源,通过流式处理,完成DPI的实时统计工作,包括多粒度(5分钟/1小时/1天)去重用户统计、多粒度去重不同号码头用户统计、多粒度流量统计及多粒度去重域名统计等。4G DPI实时统计具体项目方案如图6所示:
 高层
高层 访谈
访谈

 观点
观点
